Спасибо!
Ваша заявка отправлена. В ближайшее время мы с Вами свяжемся.
Спасибо!
Ваша отзыв отправлен.
Оставить заявку
Отправить резюме
Техническое воплощение "копья Дон Кихота". Борьба с ветряными мельницами
Во второй части статьи наш эксперт Сергей Виноградов рассказывает о Customer Journey, устройстве хранилища и делится собственными наработками по устранению возникающих сложностей.

Что решили сделать?
Для начала мы хотим мониторинг. Причем два его вида.
Мониторинг
Технический мониторинг. Если какие-то компоненты pipeline задеплоены, в эксплуатации должны видеть, что происходит с компонентой: как потребляет память, CPU, диск.
Бизнес-мониторинг. Это инструмент data scientist, который позволяет абстрагироваться от технических нюансов реализации. На уровне проектирования, конструирования помогает определять, какие метрики модели должны быть доступны в мониторинге, например, распределение фичей или результаты работы скорингового сервиса.
Data scientist определяет метрики и его не должно волновать, как они попадут в систему мониторинга. Важно лишь, что он определил эти метрики и внешний вид dashboard, на котором отобразятся метрики. Дальше специалист запустил все на продакшн, задеплоил, и спустя время метрики полились в мониторинг. Так data scientist без доступа к проду может видеть, что происходит внутри модели.
Тестирование
Тестировать pipeline на консистентность. Учитывая специфику pipeline, это некий вычислительный граф. Мы хотим понимать, что граф реализуем, можно его обойти и найти из него выход.
У графа есть компоненты — модули. Все модули должны проходить unit и интеграционное тестирование. Процесс должен быть прозрачным и легким для data scientist.
Разработчик описывает модель и тесты сам или с чьей-то помощью. Помещает все в Gitlab, pipeline, настроенный Continuous Integration, поднимает, тестирует, видит результаты. Если все хорошо — идет дальше, нет — начинает заново.
Data scientist сосредоточен на модели и не знает, что под капотом. Для этого ему дается несколько вещей:
- API для интеграции с ядром самой системы через шину данных — message bus. В данном случае специалисту требуется описать, что идет на вход и что на выход из его модели, точки входа и точки стыка с разными компонентами внутри pipeline.
- После обучения модели появляется артефакт — файл XGBoost или pickle. У data scientist есть executer для работы с артефактами — это он должен интегрировать внутрь компоненты pipeline.
- Легкий и прозрачный API для data scientist для мониторинга работы компонентов pipeline — технический и бизнес мониторинг.
- Простая и прозрачная инфраструктура для интеграции с источниками данных и сохранения результатов работы.
Часто у нас работают модели, и спустя время приходит аудит, который хочет поднять всю историю работы сервиса. Аудит хочет проверить корректность работы, отсутствие фрода с нашей стороны. Нужны простые инструменты, чтобы любой аудитор, который знает SQL, мог залезть в специальное хранилище и посмотреть, как все работало, какие решения принимались и почему.
Мы заложили основу под две важные для нас истории.
Customer Journey. Это возможность использовать механизмы сохранения всей клиентской истории — того, что происходило с клиентом в рамках бизнес-процессов, которые реализованы на этой системе.
У нас могут быть внешние источники данных, например, DMP-платформы. От них мы получаем информацию о поведении человека в сети и в мобильных устройствах. Это может оказывать влияние на LTV его модели и на скоринговые модели. Если заемщик просрочит платеж, мы можем предсказать, что это не злой умысел — просто возникли проблемы. В этом случае к заемщику применяем мягкие методы воздействия. Когда проблемы разрешатся, клиент закроет кредит. Когда он придет в следующий раз, мы будем знать всю его историю. Data scientist достанет наглядную историю из модели и проведет скоринг в лайт-режиме.
Выявление аномалий. Мы постоянно сталкиваемся с очень сложным миром. Например, слабые точки внутри ускоренной оценки МФО могут быть источником автоматического фрода.
Customer Journey — концепция быстрого и легкого доступа к потоку данных, который идет через модель. Модель позволяет легко обнаруживать аномалии, которые характерны фроду в момент его массового возникновения.
Как все устроено?
Не долго думая мы взяли Kafka в качестве Message Bus patch. Это хорошее решение, которое используется у многих наших клиентов, эксплуатация умеет с ним работать.
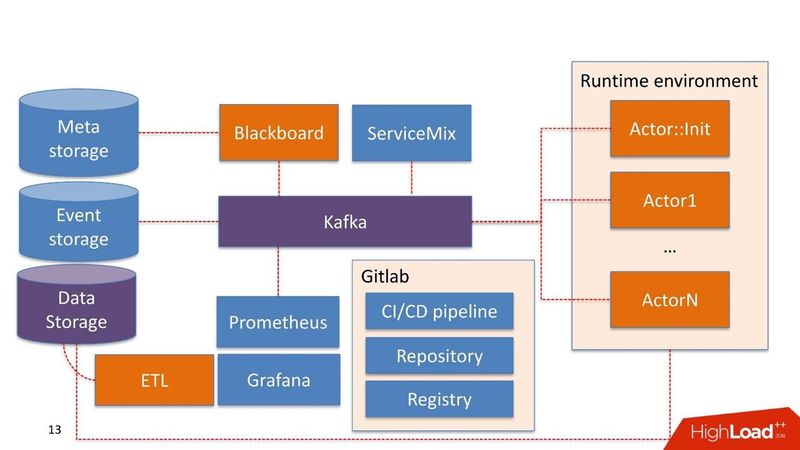
Часть компонентов системы могут уже использоваться в самой компании. Мы не строим систему заново, а переиспользуем то, что у них уже есть.
Data Storage в данном случае это хранилище, которое обычно уже есть у клиента. Это может быть Hadoop, реляционные и нереляционные БД. Мы умеем нативно работать из коробки с HDFS, Hive, Impala, Greenplum и PostgreSQL. Эти хранилища рассматриваем как источник для витрин.
Данные поступают в хранилище, проходят через наш ETL либо ETL заказчика, если он у него существует. Строим витрины, которые дальше используются внутри моделей. Data Storage у нас используется в режиме read-only.
Наши разработки
Blackboard. Название взято из одной довольно странной практики математиков 30-40 годов. Это менеджер pipelines, которые живут в админ-системе. У Blackboard есть некий Meta Storage. В нем сохраняются сами pipelines и конфигурации, которые необходимы для инициализации всех компонентов.
Вся работа системы начинается с Blackboard. Каким-то чудом pipeline оказался в Meta Storage, Blackboard спустя время это понимает, вытаскивает актуальную версию pipeline, инициализирует ее и посылает сигнал внутрь Kafka.
Есть Runtime environment. Он построен на Docker’ах и может быть растиражирован на серверы, в том числе в приватном облаке заказчика.
Из коробки идет основной Actor::Init — это инициализатор. Это джин, который умеет делать только две вещи: строить и разрушать компоненты. Он получает команду от Blackboard: «Вот pipeline, его нужно запустить на таких-то серверах с такими-то ресурсами в таких-то количествах — работай!» Дальше актор все это запускает.
Математически актор — это функция, которая на вход он принимает один или больше объектов, внутри изменяет состояние объектов по некоему алгоритму, на выходе порождает новый объект или изменяет состояние существующего.
Технически актор — программа на Python. Запускается в Docker-контейнере со своим окружением.

Актор не знает о существовании иных акторов. Единственная сущность, которая знает, что кроме актора существует весь pipeline в целом — это Blackboard. Он отслеживает состояние выполнения всех акторов внутри системы и ведет актуальное состояние, которое выражается в мониторинге как картина всего бизнес-процесса в целом.
Actor::Init порождает множество Docker-контейнеров. Кроме этого, акторы умеют работать с Data storage.
В самой системе есть компонента Event Storage. В качестве Event Storage используем ClickHouse. Его задача проста: вся информация, которой обмениваются между собой актор через Kafka, сохраняется в ClickHouse. Делается это для дальнейшего аудита. Это лог работы pipeline.
Также акторы могут быть разработаны для Customer Journey. Они видят изменения лога pipeline, и могут на лету перестраивать витрины, которые нужны для работы моделей или компонентов с правилами, уже внутри pipeline. Это непрерывный процесс изменения данных.
Мониторинг достаточно примитивно построен на Prometheus. Актору дается базовый API, и в закрытом режиме, но достаточно прозрачно для разработчика, он посылает в Kafka сообщения с метриками. Prometheus вычитывает метрики с Kafka и сохраняет в своем хранилище.
Для визуализации используем Grafana.
Две точки интеграции
Первая — точка интеграции с источниками данных, которые проходят через ETL в хранилище данных. Вторая точка интеграции, когда сервис используется уже потребителем данных, например, скоринговым сервисом.
Мы взяли Apache ServiceMix. По опыту эти точки интеграции однотипные с однотипными протоколами: SOAP, RESTful, реже очереди. Каждый раз разрабатывать свой конструктор или сервис, чтобы сгенерировать очередной SOAP-сервис мы не хотим.
Каждый раз разрабатывать свой конструктор или сервис, чтобы сгенерировать очередной SOAP-сервис мы не хотим.
Поэтому берем ServiceMix, описываем в SDL, в котором сконструированы модели данных этого сервиса и методы, которые в нем существуют. Дальше продавливаем роутером внутри ServiceMix, и он генерирует сам сервис.
От себя мы добавили хитрое синхронно-асинхронное преобразование. Все запросы, которые живут внутри системы — асинхронные и идут через Message Bus.
В массе скоринговые сервисы синхронные. Запросы ServiceMix поступают через REST либо SOAP. В этот момент он проходит через наш Gateway, который сохраняет знания о HTTP сессии. Дальше посылает сообщение в Kafka, оно пробегает через какой-то pipeline, и порождается решение.
При этом решения может еще и не быть. К примеру, что-то отвалилось, либо есть жесткий SLA на принятие решения, и Gateway отслеживает: «ОК, я получил запрос, он пришел мне в другой топик Kafka, либо мне ничего не пришло, но у меня сработал триггер по таймауту». Дальше опять идет преобразование синхронного в асинхронный, и в рамках той же HTTP сессии идет ответ потребителю с результатом работы. Это может быть ошибка или нормальный прогноз.
В этом месте, кстати, мы съели невкусную собаку благодаря великому и могучему Open Source. Мы использовали ServiceMix одной из последних версий, а Kafka предыдущих версий и все прекрасно работало. В этот Gateway мы писали, основываясь на тех кубиках, которые были уже в ServiceMix. Когда вышла новая версия Kafka, мы радостно ее схватили, но выяснилось, что поддержка хэддеров внутри сообщения в Kafka, которые раньше существовали, изменились. Gateway внутри ServiceMix больше с ними не умеет работать. Чтобы это понять, мы потратили массу времени. В результате построили свой Gateway, который умеет работать с новыми версиями Kafka. О проблеме написали разработчикам ServiceMix и получили ответ: «Спасибо, мы обязательно вам посочувствуем в следующих версиях!”
Поэтому мы вынуждены следить за обновлениями и регулярно что-то менять.
Инфраструктура — это Gitlab. Мы используем практически все, что в нем есть.
- Репозиторий кода.
- Continues Integration/Continues Delivery pipeline.
- Registry для ведения реестра Docker-контейнеров.
Компоненты
Мы разработали 5 компонентов:
- Blackboard — управление жизненным циклом pipeline. Где, что и с какими параметрами запускать из pipeline.
- Feature extractor работает просто — сообщаем Feature extractor, что на вход получаем такую-то модель данных, из данных выбираем нужные поля, маппируем их в определенные значения. Например, получаем дату рождения клиента, преобразуем в возраст, используем как фичу в своей модели. Feature extractor отвечает за обогащение данных.
- Rule based engine — проверка данных по правилам. Это простой язык описания, который позволяет человеку, знакомому с построением блоков
if, else, описать правила для проверки внутри системы. - Machine learning engine — позволяет запускать executor, инициализировать обученную модель и подавать её на вход данные. На выходе модель данные забирает.
- Decision engine — движок принятия решений, выход из графа. Имея каскад моделей, например, разные ветки оценки заемщика, вы должны каком-то месте принять решение о выдаче денег. Набор правил для решения должен быть простым. Например, у нас есть анализ LTV-модели — прогноз заработка определенной суммы денег, если прогнозируемая сумма меньше пороговой, ответ трицательный.
- ML
- Data Science
- Gitlab
- data scientist
- кейс
- IT-решения
- pipeline
- Kafka
- customer journey
Оставить комментарий