Спасибо!
Ваша заявка отправлена. В ближайшее время мы с Вами свяжемся.
Спасибо!
Ваша отзыв отправлен.
Оставить заявку
Отправить резюме
Пример решения, которое всё-таки нужно «доработать напильником» до идеала
Третья – завершающая часть серии приводит нас к готовому решению через деплой, открывает тайну времени и знакомит с дальнейшими планами развития направления.

Пример работы
Рассмотрим пример скорингового сервиса с двумя наборами входных данных. Первый — анкета заемщика, которую он сам заполняет. Второй — кредитная история из бюро кредитных историй, которая повествует о его финансовой дисциплине.
Так выглядит pipeline в этом синтетическом примере.
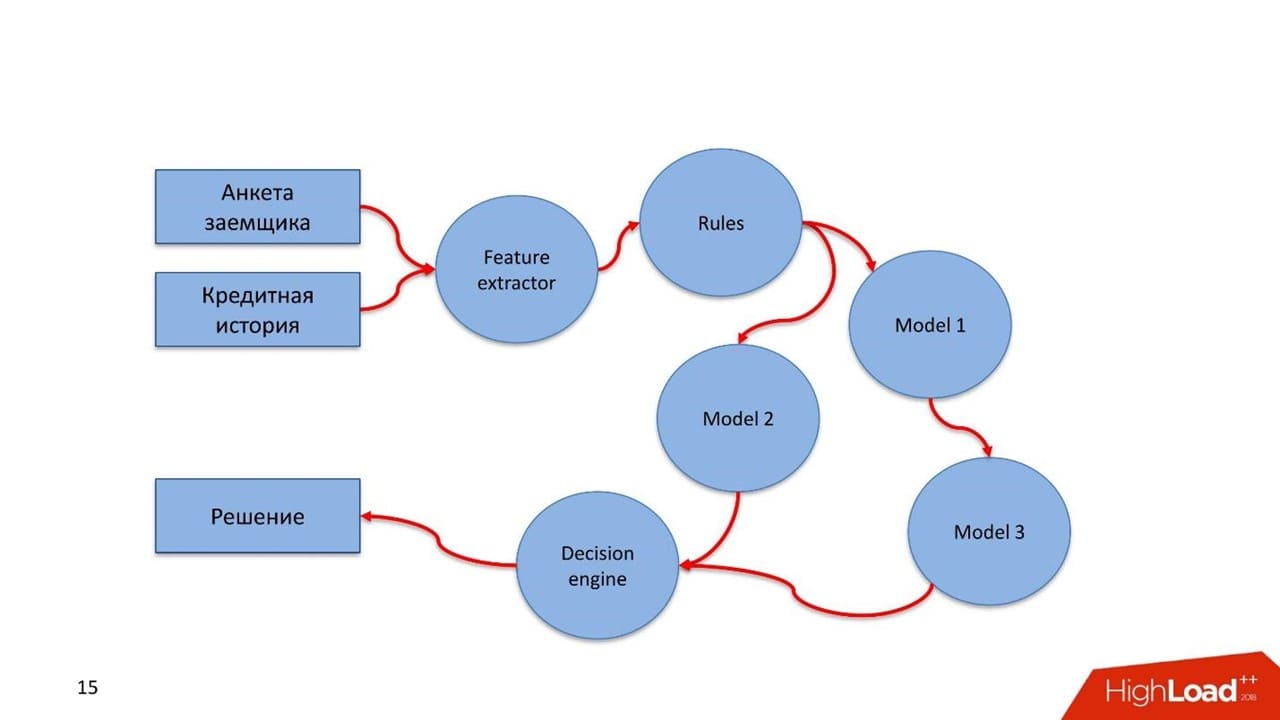
- Разработчик описывает Feature extractor: какие фичи, какие данные извлекаем из анкеты и кредитной истории, в каком виде подаем в модель.
- Набор правил. Например, проверка стоп-факторов: реальность паспорта, валидность, действительная дата рождения и возраст больше 18.
- Описывается набор моделей. В зависимости от типа, заемщик оценивается разными моделями. Если разработчик придумал еще модель, которая использует результаты работы предыдущей модели, то также здесь описывает и вставляет в pipeline.
- Формируется Decision engine. В нем описываются правила принятия решений на основании результатов работы моделей и правил.
- Порождается решение.
Все это описываем с помощью yaml. На текущий момент пока нет никакой визуальной формы описания. Мы думали об этом, но сил, времени и ума сделать это пока не хватило. Поэтому мы сделали это с помощью текстового редактора и языка yaml.
Разработчик pipeline, описывая все компоненты, указывает их тип: feature extractor, rules, models, decision engine, ее имя и версию. Это важно — на основании имени и версии генерируется Docker-контейнер. Это ссылка на Registry, где живут Docker-контейнеры. Актор-инициализатор, который их вызывает, обращается по этому имени. Поэтому, если ошибиться, то при сборке будет создан Docker-контейнер с этим именем и останется на века.
Pipeline
Мы хотели сделать все быстрее, поэтому стали писать на Python — мы его знаем и умеем на нем быстро писать. Feature extractor, правила, модели и decision engine сделали на Python.
Pipeline нарисовали на yaml. Хранение описания системного окружения в meta storage мы еще не доделали — это выполняется руками.
Если Runtime environment растиражирован на 10 серверах, то Blackboard должен знать, что он этот pipeline должен запустить на 10 серверах. Можно указать, где и какие конкретно компоненты запустить: серверы, правила, IP-адреса для точки входа Kafka, порты, топики. Пока это все работает в ручном режиме.
Все артефакты сохраняются в GitLab. Развертывание и изначальная инициализация производятся Ansible. Оказалось, что это сложный процесс. Условно большая инфраструктура на пару десятков серверов разворачивается за несколько часов, но наш инженер эксплуатации написал 50 000 строк кода на Ansible для этого.
Как выглядит деплой?
В GitLab есть pipeline. Разработчик закоммитил в GitLab. CI увидел процесс, заметил новый артефакт, прогнал тесты, породил результаты. Дальше вступает GitLab Runner, в нем конструируются Docker-контейнеры всех компонентов, которые описаны в pipeline. Если удалось собрать — все сохраняется в Registry.
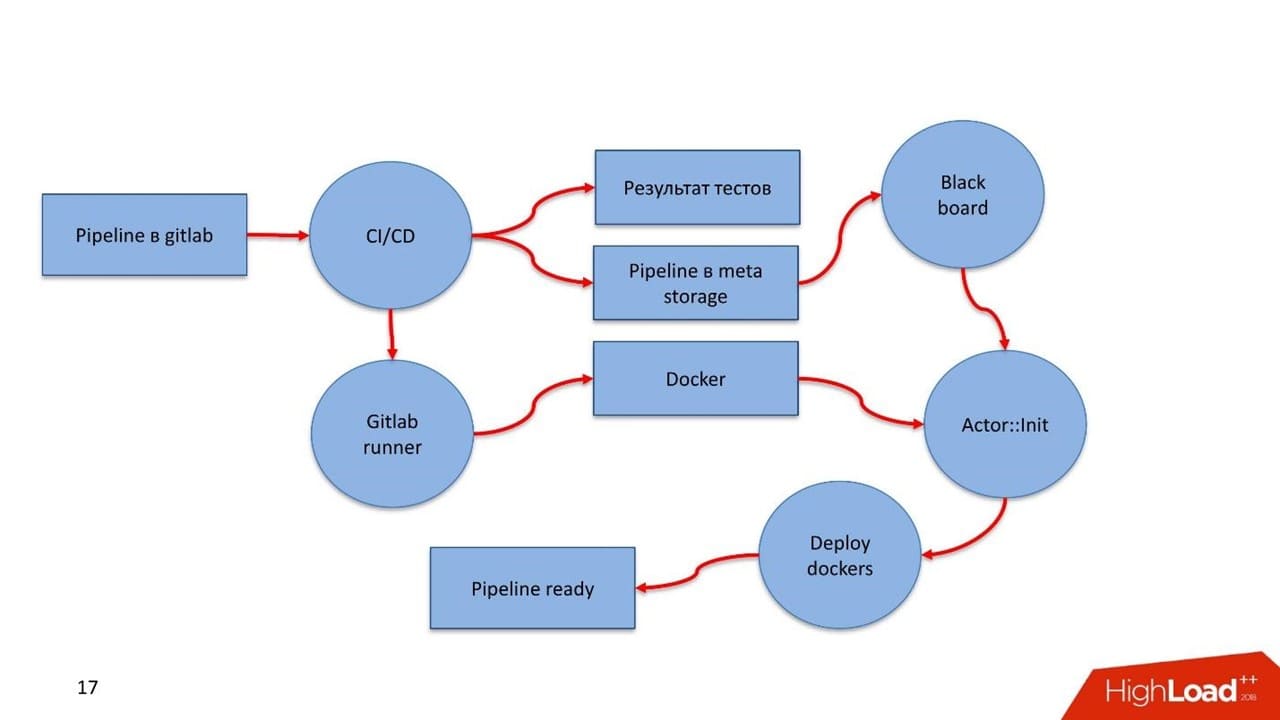
Преимущество Docker в том, что мы отстраняемся от проблем с версионностью. В каждом Docker-контейнере для каждой компоненты существует своя версия необходимых библиотек. В итоге CI pipeline сохраняет само описание pipeline в бизнес-процессах в Meta Storage, с которым работает Blackboard.
Blackboard регулярно заглядывает в Meta Storage — увидел новые изменения, достал, провалидировал, разослал сообщения актору-инициализатору. Тот подтянул Docker-контейнер и спустя несколько минут растиражировал, поднял, запустил.
Актор-инициализатор получает от Blackboard из Meta Storage все необходимые для запуска конфигурационные параметры: подключения к БД, к Kafka, к системе мониторинга. Любую информацию, которая должна быть конфигурируема, про которую Docker-контейнер изначально ничего не знает, он получает в момент инициализации.
Лампочки загорелись, в мониторинге появились Docker-контейнеры, засветились — pipeline готов!
Изначально мы разрабатывали все в DigitalOcean. Потом научились деплоить в AWS и Scaleway, но последний не очень любим.
Для наших заказчиков главное, что все это может крутиться внутри его периметра. Весь pipeline и вся его инфраструктура может находиться под управлением заказчика. Гарантировано, что нет никаких утечек.
Жизненный цикл ML состоит из трех частей. В первой от бизнеса поступает задача. Во второй data scientist’ы готовят данные и строят модель. В третьей части начинается самое интересное – хаос.
А это вообще быстро?
Сложно оценивать — формальные критерии непросты. К примеру, самый сложный pipeline, который мы делали на real-time запросах был такой.
- 2 Feature extractor входных данных. Размер данных чуть меньше 1 Мб, т.е. json с колоссальным количеством данных.
- 8 моделей — 8 экземпляров ML engine. Все они крутились на базе XGBoost.
- 18 блоков наборов правил в RB engine (115 ФЗ). В блоках 1000 правил проверки на отмывание доходов.
- 1 decision engine.
Сейчас этот сервис крутится и обрабатывает 200 запросов в секунду. Через 2 Feature extractor, 8 моделей, 18 блоков и 1 decision engine принятие решения занимает в среднем 1,2 с.
Планы
Discovery ресурсы. Автоматически отслеживать, что отвалились какие-то серверы не получается. О том, что сервер отвалился в момент деплоя, узнаем в процессе деплоя. Над решением сейчас работаем. Все ресурсы руками описываем в Meta Storage.
Визуальное проектирование pipeline. Хотим внедрить некий движок, как BPM. С ним разработчик не будет писать в yaml с кучей синтаксических и орфографических ошибок, а будет визуально двигать кубики, доставать из репозитория готовые и рисовать.
Поддержку акторов на других языках. Сейчас ради эксперимента пишем актор на Java, Scala, R. Само ядро на Python, но актор исполняется независимо от всей системы, и язык может быть любой. Достаточно обеспечить набор API на других языках, чтобы разработчик pipeline мог писать акторы на знакомом языке.
Что в итоге?
Первая версия разработки — это месяц работы двух человек. До продуктового решения — еще полгода работы. В результате получили конструктор, которым сами с трудом научились пользоваться. С трудом, потому что образ конструктора потребовал несколько итераций и подходов. Все что выше описано — его состояние на ноябрь 2018 года.
В попытках эксплуатации конструктора мы натыкались на любопытные грабли, обходили и научились с ним работать. И не зря — легче жить и нам, и эксплуатации клиентов, у которых используется конструктор.
Процесс понятен и для разработчиков, и для эксплуатации. Мы ушли от многих проблем, которые связаны с тем, как этот несчастный notebook вывести на прод, как модель мониторить и деплоить.
- ML
- Data Scence
- Gitlab
- data scientist
- кейс
- IT-решения
- pipeline
Интересно, но мне кажется история несколько преувеличена.
Оставить комментарий